IDS: Intrusion Detection System
intrusion detection system concepts and techniquesIDS: Intrusion Detection System
intrusion detection system concepts and techniques
استفاده از الگوریتم های ژنتیک برای تشخص نفوذ در شبکه
چکیده :
این متن تکنیک اعمال نمودن الگوریتم ژنتیک را در سیستمهای تشیخص نفوذ شرح می دهد.یک مرور کلی و خلاصه از سیستمهای تشخیص نفوذ و تکنیک های تشخیص و الگوریتم های ژنتیک نیز آورده خواهد شد.پارامتر ها و پروسه تکامل الگوریتم ژنتیک نیز به صورت تشریحی و با جزییات مورد بحث قرار داده می شود.بر عکس دیگر مسایل مشابه ، این پیادهسازی هر دو نوع اطلاعات زمانی و فضایی از اتصال شبکه را به صورت رمز نمودن اطلاعات اتصال شبکه به قوانین در سیستم تشخیص نفوذ مورد بحث قرار می دهد.این شیوه برای تشخیص رفتار های ناهنجار پیچیده مفید است.این پرژه بر روی پروتوکل های شبکه TCP/IP متمرکز شده است.
مقدمه :
در سالهای اخیر سیستمهای تشخیص نفوذ (IDS) به یکی از داغترین زمینههای تحقیقاتی در بحث امنیت کامپیوتر تبدیل شده اند. این شیوه یک تکنوإوژی مهم تشخیص است و یک راه مقابله برای حفظ جامعیت دادهها و در در دسترسی بودن سیستم در خلال یک عملیات نفوذ می باشد.
هنگامی که یک نفوذ کرد تلاش میکند به یک سیستم اطلاعاتی را هم بشکند و یا یک عمل غیر قانونی را که مجاز نیست انجام بدهد ، این فعالیت به عنوان یک نفوذ در نظر گرفته می شود.نفوذگرا را میتوان در دو گروه قرار داد داخلی و خارجی که اشاره به آنهایی دارد که دسترسی مجاز(تصویب شده) به سیستم دارند و آنهایی که با استفاده از یکسری تکنیک های نفوذ به سیستم حمله می کنند.
تشخیص نفوذ میتواند با استفاده از اشکالات نرمافزار ، تنظیمات نادرست ، در هم شکستن رمز عبور ، مانیتور نمودن ترافیک شبکه ای غیر ایمن شده و یا بهره برداری از عیب های طراحی پروتوکل ی معین انجام شود
یک سیستم تشخیص نفوذ سیستمی است برای تشخیص نفوذ و گزارش آنها با دقت کامل به فرد مناسب.
سیستمهای تشخیص نفوذ معمولاً به سیستمهای اطلاق میشوند که به عنوان ابزاری مهم در همه امور مربوط به خط مشی امنیتی یک سازمان عمل میکنند و عملکرد سازمان را بوسیله تعریف قوانین مربوطه برای فراهم آوردن امنیت ، مدیریت نفوذ و بازیابی آسیب های ایجاد شده بوسیله نواقص امنیتی را منعکس می نماید.
دو شاخه اصلی از تکنیک های مربوط به تشخص نفوذ وجود دارند که مورد تأیید عمومی می باشد.
تشخص سو استفاده (misuse) و تشخیص ناهنجاری (anomaly) .تشخیص سوءاستفاده به تکنیک های اطلاق میشود که متد های شناخته شده برای نفوذ به یک سیستم را مشخص می کند. این نفوذ ها به عنوان الگو(pattern) یا امضا(signature) مشخص میشوند که سیستم تشخیص نفوذ به دنبال آن است.امضا/الگو ممکن است که یک رشته ایستا باشند (static string) یا دنباله ای از عملیات هاست و پاسخ سیستم بر اساس نفوذ تشخیص داده شده می باشد.تشخیص ناهنجاری به تکنیک هایی اطلاق میشود که رفتار های قابل قبول و نرمال یک سیستم را تعریف و مشخص میکنند ( برای مثال میزان مصرف پردازنده ، زمان اجرا ، فراخوانی های سیستم) و رفتار هایی که از رفتار های نرمال و مورد انتظار سیستم خارج میشوند به عنوان نفوذ مورد بررسی قرار می گیرند.
سیستمهای تشخیص نفوذ را میتوان با توجه به مکانی که برای جستجوی رفتار های نفوذی قرار میگیرند را به دو گروه تقسیم نمود. سیستمهای تشخیص نفوذ بر پایه شبکه (NIDS) و سیستمهای تشخیص نفوذ بر پایه هاست (HIDS) .سیستم های تشخیص نفوذ بر پایه شبکه به سیستمهای اطلاق میشوند که نفوذ را بوسیله نظارت بر ترافیک ورودی و خروجی دستگاههای شبکه انجام می دهند(برای مثال کارت رابط شبکه NIC) .سیستم های تشخیص نفوذ بر پایه هاست فایلها و پردازش های فعال یک محیط نرم افزاری که مربوط به یک میزبان خاص میباشد را مورد نظارت قرار می دهند.برخی از سیستمهای تشخیص نفوذ بر پایه هاست علاوه بر عملکرد نرم افزاری به ترافیک شبکه برای تشخیص حملات به میزبان خود نیز توجه دارند . البته تکنیک های در حال ظهور و تکامل دیگری نیز وجود دارند.برای مثال سیستمهای تشخیص نفوذی که به Blocking IDS معروف هستند که سیستمهای تشخیص نفوذ بر پایه هاست را با توانایی ویرایش قوانین دیوار آتش ترکیب می کنند. نمونه دیگر که HoneyPot نامیده میشود که به عنوان یک طعمه هدف برای شخص مزاحم در نظر گرفته میشود و مشخصاً برای تلگه گذاری برای مزاحم طراحی شدهاند و با استفاده از آنها میتوان محل مزاحم را تشخیص و به حملات او پاسخ داد.
سیستمهای تشخیص نفوذ هوشمند (IIDS) نیز از پروژه های در حال انجام در مرکز تحقیقات کامپیوتری (Center for Computer SecurityResearch (CCSR)) در دانشگاه ایالتی می سی سی پی است.که در آن شیوههای مختلف برای مسائله سیستم تشخیص نفوذ با یکدیگر ترکیب میشوند و شامل تکنیک های مختلف هوش مصنوعی برای کمک به تشخیص رفتار نفوذگرانه .در این روش از تکنیک های تشخیص ناهنجاری و تشخیص سوءاستفاده و هم از سیستمهای تشخیص نفوذ بر پایه شبکه و بر پایه هاست استفاده می شود.بعضی از نرمافزار های تشخیص نفوذ متن باز که شامل همه این امکانات نیز هستند برای استفاده به عنوان سنسور های امنیتی مجتمع شده اند.مثل Bro و Snort .تکنیک هایی که در ادامه خواهیم دید قسمتی از تحقیقات در خصوص سیستمهای تشخیص نفوذ هوشمند می باشد.
الگوریتم های ژنتیک به روشهای مختلفی در سیستمهای تشخیص نفوذ مورد استفاده قرار می گیرند.بر پایه تحقیقی که در دانشگاته تگزاس انجام گرفته است(Sinclair, Pierce, and Matzner 1999) از تکنیک های مختلف یادگیری ماشین مثال finite state machine ،درخت تصمیم گیری و الگوریتم ژنتیک برای تولید قوانین هوشمند برای سیستمهای تشخیص نفوذ استفاده می کند.یک اتصال شبکه و رفتار های وابسته به آن میتوانند به نحوی ترجمه شوند تا قوانینی را به نمایش بگذارند که بتوان با استفاده از آنها در خصوص اینکه آیا این اتصال در لحظه ( بهنگام) real-time به عنوان یک نفوذ در نظر گرفته شود قضاونت نمود.قوانین میتوانند به عنوان کروموزم های داخل جمعیت مدل شوند.این جمعیت تاز زمانی که معیاری های ارزیابی بر آورده شوند تکامل(evolves) می یابند.مجموعه قوانین تولید شده به عنوان دانش درونی یک سیستم تشخیص نفوذ برای قضاونت در مورد اینکه آیا اتصال شبکه و رفتار های مربوط به آن بصورت بالقوه نفوذگرانه هستند یا خیر.
آزمایشگاه COAST در دانشگاه Purdue(Crosbie and Spafford, 1995) سیستم تشخیص نفوذی را ایجاد نمودند که از عامل های مستقل (autonomous agents) -سنسورهای امنیتی- و اعمال هوش مصنوعی برای تکامل الگوریتم های ژنتیک استفاده نموده است.عامل ها به عنوان کروموزوم ها مدل شدهاند و یک ارزیابی داخلی نیز درون هر عامل مورداستفاده قرار گرفته است.(Crosbie and Spafford, 1995).
در روشهای که در بالا شرح داده شد ، سیستم تشخص نفوذ را میتوان به عنوان سیستم بر پایه قانون (RBS) تصور نمود و الگوریتم ژنتیک به عنوان یک ابزار برای کمک به تولید دانش برای این سیستم بر پایه قانون در نظر گرفته می شود.این شیوه دارای معایبی است .به منظور تشخیص رفتار های نفوذگرانه برای یک شبکه محلی ، اتصال شبکه باید برای تعریف و مشخص نمودن رفتار های نرمال و عادی و غیر طبیعی مورد استفاده قرار گیرد.گاهی اوقات یک مله میتواند اسکن ساده پورت های در دسترس یک سرور باشد یا یک طرح برای حدس زدن رمز عبور.اما به صورت معمول این حملات بسیار پیچیدهتر هستند و بعضا نیز بوسیله ابزار های اتوماتیک که در اینترنت هم به صورت مجانی در دسترس هستند تولید می شوند.
یک مثال میتواند اسبهای تروا و یا backdoor ها باشند که میتوانند برای مدت طولانی اجرا شوند ، یا از مکانهای مختلفی آغاز شوند.برای تشخیص چنین نفوذ هایی هم اطلاعات زمانی و مکانی ترافیک شبکه باید در مجموعه قانون موجود باشد.کاربردهای فلعی الگوریتم ژنتیک این موضوع را پشتیبانی نمی کنند(temporal and spatial information. ). در ادامه نشان میدهیم چگونه اطلاعات اتصال شبکه میتواند به عنوان کروموزوم ها مدل شوند و چگونه میتوان پارامتر های درون الگوریتم ژنتیک در این رابطه تعریف نمود.مثال هایی برای نشان دادن این موضوع آورده خواهد شد.
برای مشاهده کامل این مقاله می توانید از لینک زیر استفاده کنید:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.89.3125&rep=rep1&type=pdf
انتخاب والد در الگوریتم های ژنتیک
انتخاب والد پروسهای انتخاب والدینی است که قرار است با یکدیگر ترکیب شده و اولاد هایی را برای نسل بعدی ایجاد کنند. انتخاب والد برای نرخ همگرایی یک الگوریتم ژنتیک بسیار حیاتی است و انتخاب خوب والدین الگوریتم ژنتیک را به راه حل های بهتر و مناسبتر سوق می دهد.
انتخاب یک راه حل در جمعیتی با تعداد کمی از نسل ها میتواند میزان تنوع در راه حلها را بکاهد.بنابراین حفظ تنوع خوب در جمعیت در موفقیت الگوریتم ژنتیک بسیار حیاتی است .در نظر گرفته شدن کل یک جمعیت بوسیله یک راه حل بسیار خوب تحت نام همگرایی نابهنگام (premature convergence) نامیده میشود که یک وضعیت نامطلوب در الگوریتم ژنتیک است.
انتخاب مناسب برازش (Fitness Proportionate Selection)
انتخاب برازش مناسب یکی از شیوههای مرسوم در انتخاب والد می باشد.در این روش هر شخصی میتواند با توجه به احتمال متناسب با برازش خود یک والد باشد.بنابراین اشخاص مناسبتر دارای شانس بالاتر برای زاد و ولد و انتشار ویژگیهای خود به نسل های بعدی دارند.بنابراین این استراتژی در انتخاب موجب میشود که افرادی که درای شایستگی بیشتری در جمعیت هستند انتخاب شوند و ویژگی های این افراد در طول زمان رشد و نمود پیدا کند
یک چرخ دایرهای شکل را در نظر بگیرید.چرخ به n تکه تقیسیم شده است.در واقع n نشان دهنده شماره شخص در جمعیت می باشد.هر شخص یک قسمت از دایره را در اختیار دارد که فضایی که در اختیار شخص است نشان دهنده تناسب مقدار برازش آن شخص می باشد.دو شیوه برای انتخاب برازش مناسب امکانپذیر میباشد
انتخاب چرخ رولت.Roulette Wheel Selection
در انتخاب چرخ رولت ، چرخ دایرهای (مدور) به همان شکلی که قبلاً توضیح داده شد تقسیم شده است.همانگونه که در شکل نشان داده خواهد شد یک نقطه ثابت در پیرامون چرخ انتخاب میشود و سپس چرخ ، چرخانیده میشود .ناحیه ای از چرخ که در جلوی نقطه ثابت در نظر گرفته شده قرار گیرد به عنوان والد انتخاب می شود.برای انتخاب والد دوم رویه ای مشابهی تکرار می شود. در شکل زیر استفاده از روش چرخ رولت نشان داده شده است

واضح است که فرد مناسبتر دارای سهم بزرگتری در چرخ است و بنابراین شانس بیشتری هم برای ایستادن در مقابل نقطه ثابت هنگامی که چرخ ، چرخانیده میشود دارد.شانس انتخاب یک فرد به طور مستقیم وابسته به مقدار برازش آن است.
در قسمت ذیل یک شبکه کد برای انتخاب توسط چرخ رولت آورده شده است :
for all members of population
sum += fitness of this individual
end for
for all members of population
probability = sum of probabilities + (fitness / sum)
sum of probabilities += probability
end for
loop until new population is full
do this twice
number = Random between 0 and 1
for all members of population
if number > probability but less than next probability then you have been selected
end for
end
create offspring
end loop
نمونه برداری فراگیر تصادفی :Stochastic Universal Sampling (SUS)
.
نمونه برداری فراگیر تصادفی کاملاً مشابه روش انتخاب والد به شیوه چرخ رولت است ، هرچند بجای اینکه تنها یک نقطه ثابت بر روی چرخ داشته باشیم در این شیوه همانگونه که در شکل نشان داده شده است چندین نقطه ثابت بر روی چرخ داریم.بنابراین همه والد ها تنها در یک چرخش از چرخ(دایره) انتخاب می شوند.این شیوه از انتخاب والد اجازه میدهد که افراد که لیاقت بالایی دارند حد اقل یک بار شانس انتخاب شدن داشته باشند.

این نکته را باید بازگوکنم که متدهای انتخاب برازش مناسب در مورادی که برازش میتواند مقدار منفی دریافت کند عمل نمی کنند.
انتخاب مسابقهای (تورنومنتی)
در انتخاب K-Way تورنومنتی ، تعداد k شخص را از بین جمعیت به شکل تصادفی انتخاب میکنیم و بهترین آنها را به عنوان والد بر می گزینیم.پروسه ای مشابه برای انتخاب والد بعدی به همین صورت تکرار می شود.شیوه انتخاب به صورت تورنومنتی برای موقعیت هایی که برازش مقدار منفی دارد نیز مناسب است.


تابع برازش (Finness function)
تعریف ساده از تابع برازش ، تابعی است که راه حل کاندید برای یک مسائله را به عنوان ورودی دریافت میکند و یک خروجی را که میزان خوب بودن راه حل را مشخص میکند ارایه میکند که این کار با توجه به مسائله ای که با آن سر و کار داریم در نظر گرفته می شود..محاسبه مقدار برازش (fitness) مکرراً در یک الگوریتم ژنتیک انجام میشود و بنابراین باید به اندازه کافی سریع باشد.محاسبه آهسته و کند مقدار برازش(Finness) میتواند اثر منفی روی الگوریتم ژنتیک داشته باشد و الگوریتم را فوقالعاده کند نماید.
در اغلب مواقع تابع برازش (fitness function) و تابع هدف(objective function) شبیه یگدیگر هستند و هر دوی آنها تابع مقصود داده شده را کمینه یا پیشنه می کنند.برای مسائل پیچیده با چنید هدف و محدودیت(constraints) طراح الگوریتم ممکن است تابع های برازش مختلفی را انتخاب نماید.
تابع برازش باید دارای ویژگیهای زیر باشد :
- تابع برازش باید به اندازه کافی برای محاسبه سریع باشد.
- تابع برازش باید بصورت کمی چگونگی بدست آوردن راه حل مناسب یا چگونگی تولید افراد مناسب از راه حل بدست آمده را اندازهگیری نماید
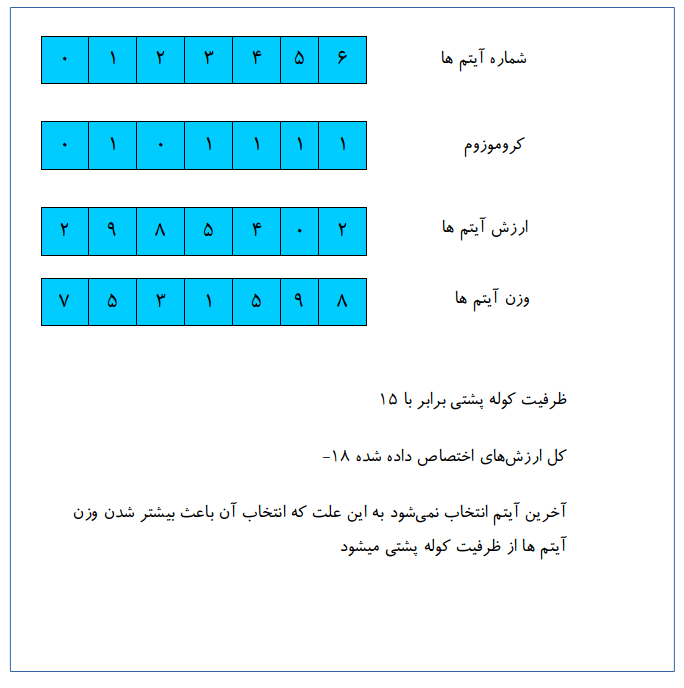
در شکل زیر محاسبه برازش برای مسائله کوله پشتی 0-1 نشان داده شده است.این یک تابع برازش ساده است که تنها مقادیر ارزش آیتم هایی که انتخاب شدهاند را جمع می بندد(آنهایی که در کروموزوم با ۱ نشان داده شده اند) ، عناصر از چپ به راست اسکن میشوند تا زمانی که کوله پشتی پر شود.