IDS: Intrusion Detection System
intrusion detection system concepts and techniquesIDS: Intrusion Detection System
intrusion detection system concepts and techniques
چرا منطق فازی - مجموعه های فازی
منطق فازی به سیستم های کامپیوتری کمک می کند تا مانند یک انسان تصمیم بگیرند و استنتاج نمایند.برای مثال هنگامی که یک دستور العمل آشپزی را دنبال می کنیم در واقع از نوعی استنتاج انسانی بهره می گیریم .مثلا سرآشپز می گوید کمی نمک این اصطلاح برای انسان ها آشناست و قابل درک اما برای کامپیوتر ها نه.منطق فازی به کمک ما می آیند تا قسمتی از استنتاج انسانی را برای سیستم های هوش مصنوعی فراهم سازد.با یک مثال این مورد را توضیح می دهم.در خصوص اندازه گیری هوش مصنوعی با سه گروه روبه رو هستیم باهوش ، حد متوسط و کودن در واقع با سه مجموعه سر و کار داریم پس طبق تعریف مجموعه های کلاسیک هر شخص عضو یکی از این مجموعه هاست و اگر عضو یکی بود نمی تواند عضو مجموعه دیگری باشد. سه مجموعه را به صورت زیر تعریف می کنیم :
کودن={۷۰ ،۷۱ …..۷۹}
حد متوسط = {۸۰ ،۸۱ ،…..۱۰۹}
باهوش= {۱۱۱،۱۱۰، …...،۱۳۰}
که نحوه نمایش گرافیکی این مجموعه های کلاسیک (CRISP SET ) به صورت زیر است.
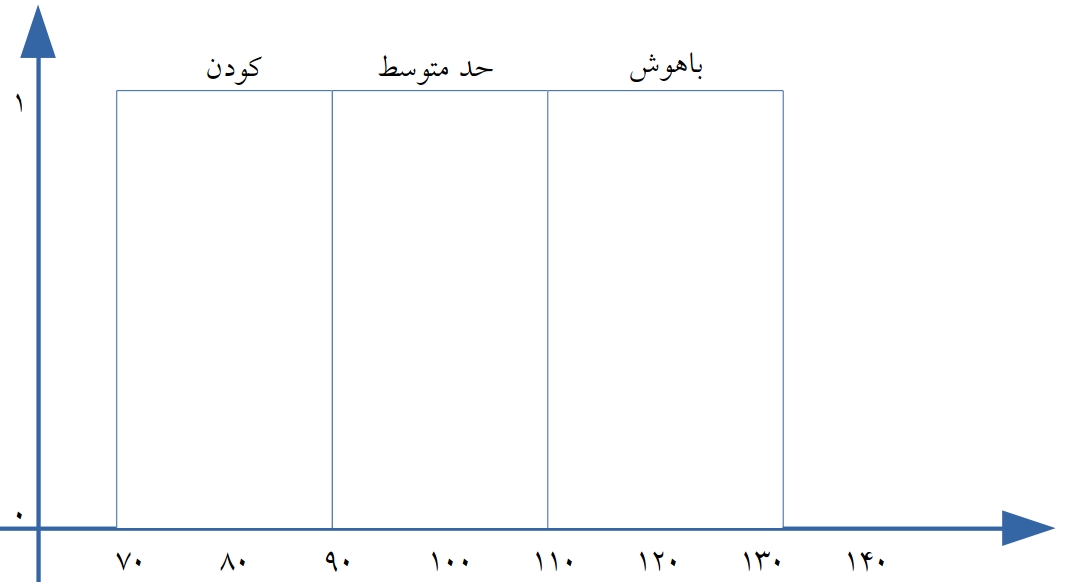
به شکل توجه کنید که درجه عضویت هر عنصر از یک مجموعه ۰ یا ۱ است.بر این اساس هوشمندی یک شخص را می توان با نسبت دادن آنها بر اساس نمره IQ که به دست آورده اند به یکی از این مجموعه ها بدست آورد.فقط یکی از مجموعه ها.حالا حالتی را در نظر می گیریم که شخص نمره تست هوش برابر ۱۰۹ دارد.مسلما هوش او بالاتر از هوش افراد حد متوسط است و شاید حتی بتوان او را جز افراد باهوش در نظر گرفت زیرا هوش او از شخصی که درای نمره هوش ۹۲ است بسیار بیشتر است اگرچه با استفاده از مجموعه های کلاسیک این دور هر دو در یک رده هوشی قرار خواهند داشت.حالا فرض کنیم شخصی دارای نمره هوشی ۷۹ و دیگری نمره ۸۰ است مسلم است که مقایسه این دو و به این نتیجه رسید که یکی باهوش و دیگری کودن است نیز عقلانی به نظر نمی رسد و این همان نقطه است که مجموعه های کلاسیک از درک آن عاجز هستند و نقطه سقوط آنهاست.مجموعه های فازی به عناصر اجازه می دهند که یک درجه اهمیت به آنها نسبت داده شود و مرزهای فازی با استفاده از توابع عضویت (membership function ) تعریف شوند. یک مجموعه فازی بوسیله تابع عضویت آن تعریف می شود.این توابع می توانند هر شکل دلخواهی داشته باشند اما معمولا پرکاربردترین آنها مثلثی و ذوذنقه ای هستند. نکته قابل توجه در همه اشکال منطق فازی انتقال تدریجی از نواجی کاملا خارج از یک مجموعه به نواحی کاملا داخل مجموعه می باشد که در شکل ذیل که مربوط به نمایش مثلی عبارات زبانی کودن ، حد متوسط و باهوش است قابل مشاهده است که این روند یک مقدار را قادر می نماید تا در یک مجموعه دارای عضویت بخشی ( جزیی) Partial membership باشد.در این شکل خط نقطه چین نشان دهنده چگونگی وضعیت مغزی شخص است.کسی که تست هوش وی برابر با ۱۱۵ باشد عضو دو گروه خواهد بود اما با درجه عضویت های متفاونت.همانگونه که نقطه تقاطع خط چین با مجموعه ها نشان می دهد درجه عضویت وی در مجموعه باهوش ها برابر با ۰.۷۵ و درجه عضویت وی در مجموعه حد متوسط ها برابر ۰.۲۵ است .این روش دقیقا مشاهبه عملکر استنتاج انسانی در خصوص هوشمندی افراد است.
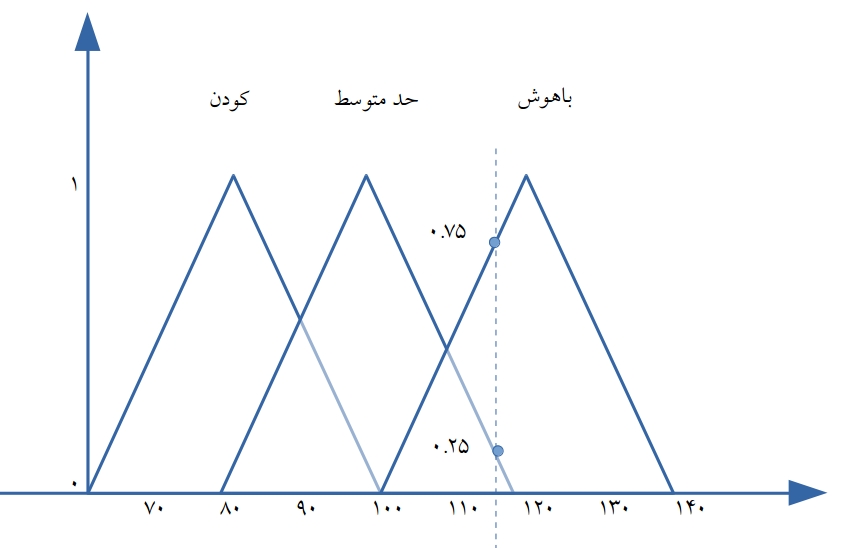
انسان این شخص را بیشتر باهوش می داند تا دارای هوش متوسط و این چیزی است که می تان از مقادیر عضویت مجموعه فازی وی می توان استنباط نمود.
معرفی منطق فازی
مقدمه :
سیستم های منطق فازی (fuzzy logic systems -fls) یک خروجی قابل قبول اما قطعی در پاسخ به یک ورودی ناقص ، مبهم ، تحریف شده و یا نادرست (fuzzy) تولید می کنند.
منطق فازی (Fuzzy Logic -FL) یک نوع مدل استدلال است که استدلال انسانی را شبیه سازی می کند.شیوه منطق فازی راه حل تصمیم گیری انسانی را تقلید میکند به طوری که همه امکان های میانی بین مقادیری دیجیتال بله یا خیر را در نظر گرفته و در حل مسائله درگیری می کند.
بلاک منطقی مرسوم که یک کامپیوتر آن را درک میکند و متوجه میشود یک ورودی قطعی را دریافت میکند و یک خروجی صریح را تولید میکند که این خروجی صحیح( TRUE ) یا غلط است ( FALSE). این خروجی ها شبیه بله یا خیر انسانی هستند.مخترع منطق فازی ،پرفسور لطفی زاده ، کشف نمود که بر خلاف کامپیوتر ها ، تصمیم های گرفته شده توسط بشر شامل یک محدوده از چیز های ممکن در میان بله و خیر است.از قبیل :
CERTAINLY YES -قطعا بله
POSSIBLY YES – احتمالاً بله
CANNOT SAY – نمیشه گفت
POSSIBLY NO -احتمالا نه
CERTAINLY NO – قطعاً بله
منطق فازی بر روی همه سطوح موارد(جواب های ) ممکن برای ورودی به منظور بدست آوردن یک خروجی قطعی عمل می کند.
پیادهسازی و اجرا :
سیستم منطقی فازی میتواند در سیستمهایی با اندازه ها و محدوده توانایی متفاوت از میکرو کنترلر های کوچک تا بزرگ ، شبکه ، سیستمهای کنترلر مبتنی بر ایستگاه کاری پیادهسازی و اجرا شود.
سیستم منطق فازی میتواند در سختافزار ها ، نرمافزار های و ترکیبی از هر دو پیادهسازی و اجرا شود.
چرا منطق فازی ؟
منطق فازی برای اهداف تجاری و علمی و کاربردی مفید است
- میتواند برای کنترل ماشینها و محصولات مصرف کننده به کار گرفته شود
- ممکن است که استدلال دقیقی در اختیار قرار ندهد ، اما در نهایت یک استدلال قابل قبول تولید میکند
- منطق فازی یکی از روشها یی است که میتواند در محیط های غیر قطعی کاربرد داشته باشد
یک سیستم منطق فازی ۴ بخش اصلی دارد که در ذیل به آن میپردازیم.
این قسمت از سیستم منطق فازی ورودی های سیستم را که اعداد Crisp ( همان مجموعه اعداد معمولی ) را به مجموعه فازی تبدیل می کند. این ماژول سیگنال ورودی را به ۵ مرحله تقسیم میکند ، از جمله :
LP x is Large Positive X مثبت بزرگ است
MP x is Medium Positive X مثبت متوسط است
S x is Small X کوچک است
MN x is Medium Negative X متوسط منفی است
LN x is Large Negative X بزرگ منفی است
2-پایگاه دانش : Knowledge Base
در پایگاه دانش قوانین IF-THEN هایی که توسط شخص خبره تهیه و تدوین شدهاند قرار می گیرد.
موتور استنتاج پروسه استدلال انسانی را بوسیله ایجاد استنتاج فازی بر روی ورودی و قوانین IF-THEN شبیه سازی میکند
ماژول غیر فازی ساز در نهایت مجموعه فازی تولید شده بوسیله موتور استنتاج را به مقداری عددی معمولی (Crisp ) تبدیل می کند.

تابع عضویت بر روی مجموعه های فازی از متغیر ها ،یکسری عملیات را انجام میدهند.
تابع عضویت :
تابع عضویت به ما اجازه میدهد تا که یک مجموعه فازی را به صورت گرافیکی نمایش بدهیم و موارد زبانشناسی مربوط به آن را تعیین کنیم.تابع عضویت برای یک مجموعه فازی مثل A بر روی متغیر universe of discourse مثل X به صورت :µA:X → [0,1] تعریف می شود.که در آن هر عنصر از X به مقداری بین ۰ و ۱ نگاشت می شود. که مقدار عضویت یا درجه عضویت نامیده می شود.که درجه عضویت عنصری در X را در مجموعه فازی A معین می کند.
- محمور X نشان دهنده universe of discourse است.
- محور Y نشان دهنده درجه عضویت است که بین ۰ تا ۱ متغیر است. [0,1 ].

تابع عضویت مثلثی شکل در میان دیگر شکلهای تابع عضویت مثل ذوذنقه ای ، تک صفحه (singleton) و گواسین (Gaussian) عمومیت بیشتری دارند.
در این شکل ورودی برای ۵ سطح فازی کننده از -۱۰ ولت تا +۱۰ ولت متغیر است.بنابراین خروجی متناظر نیز متغیر است.
مثالی از یک سیستم منطق فازی :
اجازه بدهید تا یک سیستم تهویه هوا را با پنج سطح سیستم منطق فازی مورد بررسی قرار دهیم.این سیستم دمای سیستم تهویه هوا را با مقایسه دمای اتاق و مقدار دمای مورد نظر ( هدف) تنظیم می کند.

الگوریتم
تعریف متغیر های زبانی و شرایط ( موارد)
ساختن توابع عضویت برای آنها
ساختن پایگاه داده دانش قوانین
تبدیل دادههای معمولی (Crisp Data ) به مجموعه های داده فازی با استفاده از توابع عضویت ( فازی سازی)
ارزیابی قوانین در پایگاه قانون (موتور استنتاج)
ترکیب نتابج هر یک از قانون ها (موتور استنتاج)
تبدیل خروجی داده به مقادیر غیر فازی (غیر فازی سازی )
توسعه منطق :مرحله اول : تعریف متغیر های زبانی و شرایط ( موارد)
متغیر های زبانی ، متغیر های ورودی و خروجی در شکل کلمات ساده یا جملات هستند.برای دمای اتاق ، سرد ، گرم و غیره و غیره موارد زبانی هستند.
Temperature (t) = {very-cold, cold, warm, very-warm, hot}
هر عضوی از این مجموعه یک مورد زبانی است و میتواند بخشی از مقادیر دما را به طور کلی پوشش دهد.
مرحله ۲ : تولید توابع عضویت برای آنها :
توابع عضویت متغیر دما در ذیل نشان داده شده است

مرحله ۳ :
ایجاغد یک ماتریکس از مقادیر دمای اتاق در مقابل مقادیر دمای هدفی که از سیستم تهویه انتظار داریم برای ما فراهم کند
دمای هدف / دمای اتاق
|
دمای هدف / دمای اتاق |
Very_Cold |
Cold |
Warm |
Hot |
Very_Hot |
|---|---|---|---|---|---|
|
Very_Cold |
No_Change |
Heat |
Heat |
Heat |
Heat |
|
Cold |
Cool |
No_Change |
Heat |
Heat |
Heat |
|
Warm |
Cool |
Cool |
No_Change |
Heat |
Heat |
|
Hot |
Cool |
Cool |
Cool |
No_Change |
Heat |
|
Very_Hot |
Cool |
Cool |
Cool |
Cool |
No_Change |
مجموعه قوانی را پایگاه دانش به شکل IF-THEN-ELSE تولید و ایجاد می کنیم.
|
Sr. No. |
Condition |
Action |
|---|---|---|
|
1 |
IF temperature=(Cold OR Very_Cold) AND target=Warm THEN |
Heat |
|
2 |
IF temperature=(Hot OR Very_Hot) AND target=Warm THEN |
Cool |
|
3 |
IF (temperature=Warm) AND (target=Warm) THEN |
No_Change |
مرحله ۴ : بدست آوردن مقدار فازی
عملیات های مجموعه فازی ارزیابی قوانین را انجام می دهند. عملیات استفاده شده برای OR و AND به ترتیبی بیشینه max و کمینه MIN می باشد.همه نتایج ارزیابی به شکل نتیجه نهایی ترکیب می شوندواین تنتیجه یک مقدار فازی است.
مرحله ۵ : انجام عملیات غیر فازی نمودن
غیر فازی نمودن انجام عملیات بر اساس تابع عضویت برای متغیر خروجی میباشد

مجموعه داده KDD CUP 1999 چیست - کاربرد ویژگی های یک اتصال شبکه برای تشخیص نفوذ
در این پست به معرفی جامع تر مجموعه داده های جمع آوری شده برای تست سیستم هایش تشخیص نفوذ تحت نام KDD CUP 1999 می پردازم و نشان خواهم داد که یک سیستم تشخیص نفوذ چگونه با استفاده از ویژگی های اتصلات شبکه پی به برای تشخیص حمله استفاده می کند و آخر نیز لینک دانلود مجموعه داده KDD CUP 1999 را قرار می دهم.
نرمافزار
های طراحی شده برای تشخیص نفوذ در شبکه ها ، کامپیوتر را در برابر کاربران
غیر مجاز و یا حتی کابران خودی محافظت می کند.وظیفه یک سیستم خود فراگیر
تشخیص نفوذ ایجاد یک مدل احتمالی ( مثلاً طبقه بندی) است که توانایی تشخیص
بین اتصلات بد که نفوذ یا حمله نامیده میشوند و اتصلات نرمال و خوب را
داشته باشند.
برنامه ارزیابی تشخیص نفوذ دارپا 1998 (DARPA
1998) بوسیله آزمایشگاههای MIT Lincoln تهیه و مدیریت شد.هدف هم بررسی و
ارزیابی سیستمهای تشخیص نفوذ بود. یک مجموعه استاندارد از دادهها مورد
بررسی قرار گرفت ، که شامل طیف گسترده ای از نفوذ های شبیه سازی شده در یک
محیط نظامی می باشد.مجموعه داده تشخیص نفوذ KDD 1999 از نسخهای از این
دیتاست استفاده و بهره برداری می کند.
آزمایش گاه های لینکولن
محیطی را برای بدست آوردن ۹ هفتهای دادهای خام TCP برای یک شبکه محلی
که شبکه محلی نیروی هوایی آمریکا را شبیه سازی مینمود پیادهسازی
نمودند.این شبکه کاملاً همانند شبکه نیروی هوایی عمل مینمود ، اما توسط
چنیدن حمله مورد ارزیابی قرار می گرفت.داده های خام آزمایشی تقریباً ۴ گیگا
بایت بود که شامل دادهای خام دودویی TCP بود که از ترافیک ۷ هفتهای شبکه
بدست آمده بود.که حاصل پردازش ۵ میلیون رکورد های مربوط به اتصلات در این
شبکه بودند. به طور مشابه دو هفته داده آزمایشی دو ملیون رکورد اتصال را به
همراه داشت. یک اتصال دنباله ای از بسته های TCP است که در زمان های تعریف
شده شروع و پایان می یابند و جریان انتقال داده از آدرس آی پی منبع به
آدرس آی پی مقصد تحت پروتکل های شناخته شدهای انجام میشود.هر اتصال به
عنوان نرمال یا حمله برچسب میخورد که دقیقاً مشخص کننده یکی از انواع
حملات می باشد.هر رکورد اتصال تقریباً شامل 100 بایت است.
حملات در ۴ دسته اصلی دسته بندی می شوند.
۱- حملات DOS (denial of service) برای مثال syn flood
۲-R2L: دسترسی غیر مجاز از یک ماشین راه دور .برای مثال حدس زدن رمز عبور
3-U2R : دسرسی غیر مجاز مجاز به دسترسی های کاربر ارشد محلی (ROOT) مثل حملات سر ریز بافر.
۴- نظارت و کاوش برای مثال اسکن نمودن پورت ها
مهم
است که یاآوری کنیم که دادههای آزمایشی(Test Data) از توزیع مشابه
دادههای آموزشی نیستند و ممکن است شامل انواع حملات خاصی باشند که در داده
آموزشی( Training Data) وجود ندارد.برخی از متخصصین نفوذ معتقدند که حملات
جدید نوعی از حملات شناخته شده هستند و داشتن ردپایی از حملات شناخته شده
برای شناخت انواع جدید آنها کافی است.مجموعه داده شامل ۲۴ نوع حمله
آموزشی و مضافا ۱۴ نوع دیگر که تنها در داده آزمایشی وجود داردند.
انواع ویژگیهای مشتق شده( derived features)
Stolfo
et al ویژگیهای سطح بالاتری را که برای تشخیص اتصال های نرمال از اتصلات
غیر نرمال( حملات) به ما کمک می نماید را تعریف می کند.چندین دسته بندی
برای ویژگیهای مشتق شده وجود دارد.ویژگی Same Host تنها اتصالاتی را که
در دو ثانیه قبل مقصد مشابهی در اتصال جاری داشتهاند را مورد آزمایش قرار
میدهد و آمار های وابسته به پروتوکل رفتاری آن را محاسبه می نماید.به شکل
مشابهی ویژگی Same Service تنها اتصالات در دو ثاینه قبل را که سرویس
مشابهی در اتصال جاری داشتهاند را مورد آزمایش قرار می دهد.ویژگی های same
host و same service در کنار یکدیگر ویژگیهای ترافیکی مبتنی بر زمان
(Time Based) از رکورد های اتصال نامیده می شوند.
برخی از
حملات نظارت و کاوش (probing) هاست ها ( یا پورتها) را با استفاده از فاصله
زمانی بزرگتر از دو ثاینه اسکن میکنند ، برای مثال یک بار در
دقیقه.بنابراین رکورد های اتصال براساس هاست مقصد نیز مرتب میشوند ، و
بدین صورت ویژگیها با استفاده از یک پنجره از ۱۰۰ اتصال که هاست مشابهی
دارند ساخته میشوند و از پنجره زمانی استفاده نمی شود. این مجموعه
ویژگیهای ترافیکی بر پایه هاست نیز نامیده می شود. بر عکس حملات DOS و
نظارت و کاوش هیچ الگوی ترتیبی در رکوردهای مربوط به حملات R2L و U2R
مشاهده نمی شود.و علت آن این است که حملات DOS و نظارت وکاوش درگیری تعدای
زیادی اتصلات به تعدادی هاست در یک بازه زمانی کوتاه هستند ولی حملاتR2L و
U2R در قسمت داده بسته ها خود را جاسازی میکنند و تنها درگیر یک اتصال
خواهند بود.
در زیر لیست کاملی از رکورد های یک اتصال را در سه جدول مشاهده می کنیم.
ویژگی های ترافیکی محاسبه شده با استفاده از پنجره زمان دو ثانیه ای
| نام ویژگی | شرح | نوع |
| count | تعداد اتصلات به هاست مشابه در اتصال حاری در دو دقیقه قبل | continuous |
| Note: The following features refer to these same-host connections. نکته : ویژگیهای زیر به اتصلات same host ارجاع داده می شوند |
||
| serror_rate | % of connections that have ``SYN'' errors | continuous |
| rerror_rate | % of connections that have ``REJ'' errors | continuous |
| same_srv_rate | % of connections to the same service | continuous |
| diff_srv_rate | % of connections to different services | continuous |
| srv_count | number of connections to the same service as the current connection in the past two seconds | continuous |
| Note: The following features refer to these same-service connections. | ||
| srv_serror_rate | % of connections that have ``SYN'' errors | continuous |
| srv_rerror_rate | % of connections that have ``REJ'' errors | continuous |
| srv_diff_host_rate | % of connections to different hosts | continuous |
ویژگی های محتوایی یک اتصال که پیشنهاد داده شده اند
| نام ویژگی | شرح | نوع |
| hot | تعداد شاخص های hot | continuous |
| num_failed_logins | تعداد تلاش های برای ورود که با شکست مواجه شده اند | continuous |
| logged_in | اگر با موفقیت وارد شده باشد مقدار ۰ در غیر اینصورت ۱ | discrete |
| num_compromised | تعداد شرایط در معرض خطر | continuous |
| root_shell | اگر پوسته روت بدست آمده باشد ۰ در غیر اینصورت ۱ | discrete |
| su_attempted | اگر دستور su root به کار گرفته شده باشد ۰ در غیر اینصورت ۱ | discrete |
| num_root | تعداد دسترسی های root | continuous |
| num_file_creations | تعداد عملیات های ایجاد فایل | continuous |
| num_shells | number of shell prompts | continuous |
| num_access_files | تعداد عملیات های دسترسی کنترل فایل ها | continuous |
| num_outbound_cmds | تعداد دستورات خارجی در یک نشست ftp | continuous |
| is_hot_login | اگر ورود متعلق به لیست hot باشد ۰ در غیر اینصورت ۱ | discrete |
| is_guest_login | 1 if the login is a ``guest''login; 0 otherwise اگر ورود میهمان باشد ۰ در غیر اینصورت ۱ |
discrete |
ویژگی های پایه یک اتصال منحصر به فرد TCP
| نام ویژگی | شرح | نوع |
| duration | طول اتصال ( تعداد ثانیه ها) | continuous |
| protocol_type | نوع پروتوکل مثل TCP , UDP و غیره | discrete |
| service | سرویس شبکه در مقصد برای مثال http , telnet و غیره | discrete |
| src_bytes | تعداد بایت های داده از منبع به مقصد | continuous |
| dst_bytes | تعداد بایت های داده از مقصد به منبع | continuous |
| flag | حالت نرمال یا خطای یک اتصال | discrete |
| land | اگر اتصال از /به هاست مشابهی بود آنگاه پورت ۰ در غیر اینصورت پورت ۱ | discrete |
| wrong_fragment | تعداد فرگمنت های اشتباه | continuous |
| urgent | تعداد بسته های فوری | conti |
برای دانلود فایل های مربوط به مجموعه داده KDD CUP 1999 به لینک زیر مراجعه نمایید :