IDS: Intrusion Detection System
intrusion detection system concepts and techniquesIDS: Intrusion Detection System
intrusion detection system concepts and techniques
جمعیت در الگوریتم های ژنتیک (Population)
جمعیت (Population ) زیر مجموعهای از راه حلها در نسل فعلی است(زایش فعلی).همچنین جمعیت را میتوان به عنوان مجموعهای از کروموزوم ها تعریف نمود.چند چیز را هنگام کار با جمعیت در الگوریتم های ژنتیک به خاطر سپرد
- تنوع و گوناگونی جمعیت حتماً باید حفظ شود ، در غیر اینصرت موجب همگرایی زودهنگام می گردد(premature convergence).
- اندازه جمعیت نباید خیلی بزرگ باشد زیرا ممکن است که باغث کند شدن الگوریتم ژنتیک شود ، این در حالی است که جمعیت کوچکتر ممکن است که برای یک مخزن زاد و ولد(mating pool) به اندازه کافی مناسب نباشد.و این را مد نظر میگیریم که تصمیم برای یک جمعیت با اندازه مطلوب نیاز به آزمایش و خطا دارد.
مقدار دهی اولیه جمعیت
دو متد اصلی برای مقدار دهی اولیه یک جمعیت در یک الگوریتم ژنتیک وجود دارد که به در زیر آورده می شوند
- مقدار دهی اولیه تصادفی (Random Initialization ) . جمعیت دارد نمودن جمعیت اولیه با راه حلهای کاملاً تصادفی
- مقدار دهی اولیه اکتشافی (ابتکاری)Heuristic initialization : جمعیت دار نمودن جمعیت اولیه با استفاده از روشهای اکتشافی ( ابتکاری ) شناخته شده برای مسائله.
به صورت تجربی مشاهده شده است که راه حلهای تصادفی ، راه حلهایی هستند که جمعیت را به سمت بهینه شدن سوق میدهند .بنابراین با استفاده مقدار دهی اولیه اکتشافی ، تنها جمعیت با یک جفت راه حل خوب ایجاد میکنیم ، پس بدین منظور بقیه جمعیت را با راه حلهای تصادفی پر میکنیم به جای اینکه همه جمعیت مورد نظر خود را با راه حلهای پر پایه اکتشاف پر نماییم.
همچنین بعضا مشاهده شده است که مقدار دهی اولیه اکتشاقی در بعضی موارد سازگاری اولیه (initial fitness) جمعیت را مورد تأثیر قرار داده است اما در پایان این تنوع در راه حلها خواهد بود که منجر به بهینه سازی می شود.
مد هال جمعیت (Population Models)
دو مدل جمعیت که به صورت گسترده مورد استفاده هستند در زیر بیان میشود
- حالت پایدار (Steady State) :در الگوریتم ژنتیک حالت پایدار ، در هر تکرار یک یا دو اولاد تولید می نماییم و آنها یک یا پو شخص از جمعیت را جایگزین می نمایند.الگوریتم ژنتیک حالت پایدار به الگوریتم ژنتیک افزایشی (Incremental ) نیز مشهور است.
- نسل (Generational): در مدل نسل ، n اولاد تولید میکنیم ، که در اینجا n اندازه جمعیت میباشد و همه جمعیت توسط نسل جدیدتر در پایان تکرار تعویض می گردد.
نمایش ژنوتیپ Genotype
یکی از مهمترین تصمیم گیری ها در هنگام اجرای یک الگوریتم ژنتیک ، تصمیم در خصوص نحوه نمایشی است که برای نشان دادن راه حل مسائله از آن استفاده می کنیم. دلیل اهمیت هم آن است که نمایش نامنساب میتواند منجر به کارایی پایین الگوریتم ژنتیک گردد.بنابراین نمایش انتخاب نحوه نمایش مناسب ،تعریف مناسبی از نگاشت میان فضاهای ژنوتیپ و فنوتیپ را شامل میشود و از ملزومات موفقیت الگوریتم ژنتیک می باشد.در این بخش تعدادی از پرکاربردترین شیوههای نمایش الگوریتم های ژنتیک را نشان می دهیم.هر چند نحوه نمایش یکی از مسائل بسیار سخت است شخص ممکن است که نیاز به نحوه های نمایش دیگر داشته باشد و یا ترکیبی از نحوه های نمایشی را که توضیح داده خواهد شد را برای مطابقت با مسائله خود به کار گیرد.
نمایش دودویی :
نمایش دودویی یکی از سادهترین و پر استفاده ترین شیوههای نمایش در الگوریتم های ژنتیک است.دراین نوع از نمایش ژنوتیپ شامل رشته ای از بیتها می باشد.برای بعضی از مسائل زمانی که راه حل شامل متغیرهای تصمیم گیری بولین (yes/no ) میباشد نمایش به صورت باینری (دودویی) امری طبیعی است.برای مثال در مسائله کوله پشتی 1/0 (0/1 Knapsack Problem) .اگر n آیتم وجود داشته باشد ، میتوانیم راه حل را بوسیله یک رشته دودویی از n عنصر نمایش بدهیم ، بطوری که X امین عنصر (x th) میگوید که آیتم x برداشته شده است (۱) یا خیر (0)

برای مسائل دیگر بویژه مسائلی که با اعداد سر و کار دارند ، میتوانیم اعداد را به صورت حالت دودویی آنها نشان بدهیم.مشکل با این نوع از رمزگذاری (encoding ) این است که بیتهای مختلف دارای اهمیت متفاوتی هستند ، بنابراین عملگرهایی مثال جهش (mutation) و متقاطع (crossover ) میتوانند اثرات ناملطوبی داشته باشند.این مشکل میتواند تا حدی با استفاده از Gray Coding حل شود ، بدین صورت تغیر در یک بیت تأثیرات خیلی زیادی در حل مسائله نخواهد داشت.
نمایش مقدار دهی واقعی (Real Valued Representation):
برای مسائلی که میخواهیم ژنها را با استفاده از متغیر های متوالی بجای متغیر های گسسته تغریف کنیم ، نمایش مقدار دهی واقعی طبیعی ترین روش است.اگر چه دقت این مقدار دهی واقعی یا نقطه اعشار اعداد یکی از محدودیتها برای کامپیوتر است.در این روش نمایش مقدار هر چیزی مرتبط با مسائله میتواند باشد.و هر کروموزم میتواند شامل یک مقدار باشد.

نمایش صحیح (Integer Representation)
برای ژنهایی با مقادیر گسسته ، همیشه نمیتوانیم راه حل را به فضای دودویی yes یا no محدود نماییم.برای مثال اگر با میخواهیم چهار مسیر شمال ، جنوب ،شرق و غرب را رمزگذاری کنیم، میتوانیم آنها را به صورت {۰،۱،۲،۳} رمز گذاری نماییم.در چنین مواردی نمایش صحیحی مورد استفاده است.

نمایش جایگشتی :
در اکثر مسائل ،راه حل بوسیله ترتیبی از عناصر نمایش داده می شود.در اینگونه موارد جایگشت یکی از بهترین روشهای نمایش است.یک مثال کلاسیک از این نحوه نمایش مسائله فروشنده دورهگرد (travelling salesman problem (TSP)) است.در مسائله فروشنده یک سفر به همه شهر ها خواهد داشت، هر شهر را دقیقاً یک بار بازدید نموده و به شهری که سفر را از آن شروع نموده است باز می گردد.جمع طول کل مسیر طی شده برای این سفر باید کمترین باشد.راه حل مسائله فروشنده دورهگرد به صورت طبیعی ترتیبی یا جایگشتی از همه شهرهاست و بنابراین استفاده از نمایش جایگشتی برای این مسائله مناسب به نظر می رسد.در واقع هر کروموزم رشته ای از اعداد است که یک موقعیت را در یک دنباله نمایش می دهد

اصول و تعاریف اولیه الگوریتم های ژنتیک
اصول الگوریتم های ژنتیک
در این قسمت واژگان پایه که برای فهم الگوریتم های ژنتیک مورد نیاز است را معرفی می کنیم.همچنین ساختار عمومی الگوریتم های ژنتیک هم در شبکه کد و هم به شکل گرافیکی نمایش داده می شود.به خواننده توصیه میشود که بطور صحیح همه مفاهیم معرفی شده در این بخش را متوجه شده و همه آنها را به ذهن بسپارید .
واژگان پایه :
قبل از اینکه شروع به بحث در خصوص الگوریتم های ژنتیک نماییم ، ضروری است که با برخی از واژگان پایه و اساسی که در کل بحث الگوریتم های ژنتیک مورد استفاده قرار میگیرد آشنا شویم.
- جمعیت :(Population): یک زیر مجموعه از همه راه حلهای ( رمز شده) ممکن برای مسائله مورد مطالعه.جمعیت برای یک الگوریتم ژنتیک مشابه با جمعیت برای انسان است بجز اینکه بجای وجود انسان ها ما راه حلهای کاندید را داریم که وجود بشر را نشان می دهند.
- کروموزوم ها (Chromosomes) یک کروموزوم یک راه حل برای مسائله مورد مطالعه است.
- ژن :(Gene) ژن موقعیت عنصری از یک کروموزم است
- آلل (Allele) : مقداری که یک ژن برای یک کروموزم خاص دریافت میکند.
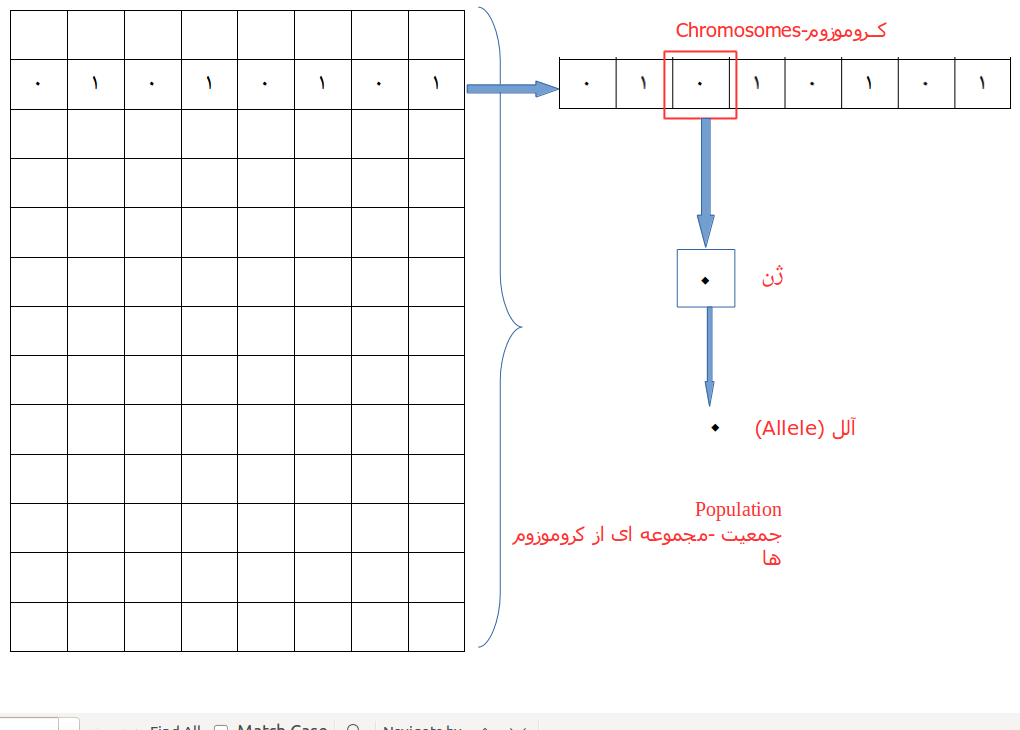
- ژنوتیپ(Genotype) : ژنوتیپ یک جمعیت در فضای محاسبات است.در فضای محاسبات ، راه حلها به شیوه ای که به راحتی قابل فهم و مدیریت بوسیله یک سیستم محاسباتی باشند نمایش داده میشوند.
- فنوتیپ (Phenotype) :فنوتیپ جمعیتی در فضای راه حل یک دنیای واقعی موجود میباشد که در آن راه حلها به شیوه ای نمایش داده میشوند که آنها در موقعیت های دنیای واقعی نمایش داده شدهاند.
- رمز گشایی و رمز گذاری (Decoding and Encoding) : در مسائل ساده فضای فنوتیپ و ژنتیپ مشابه هستند.اگرچه در اغلب موارد فضای فنوتیپ و ژنتیپ با یکدیگر متفاوت هستند.رمز گشایی فرآیند انتقال یک راه حل از فضای ژنوتیپ به فضای فنوتیپ، در حالی که رمزگذاری فرآیند انتقال از فضای فنوتیپ به ژنوتیپ میباشد.رمزگذاری باید به قدر کافی سریع باشد این فرآیند مکرراً در خلال محاسبه مقدار fitness (سازگاری) انجاممیشود.
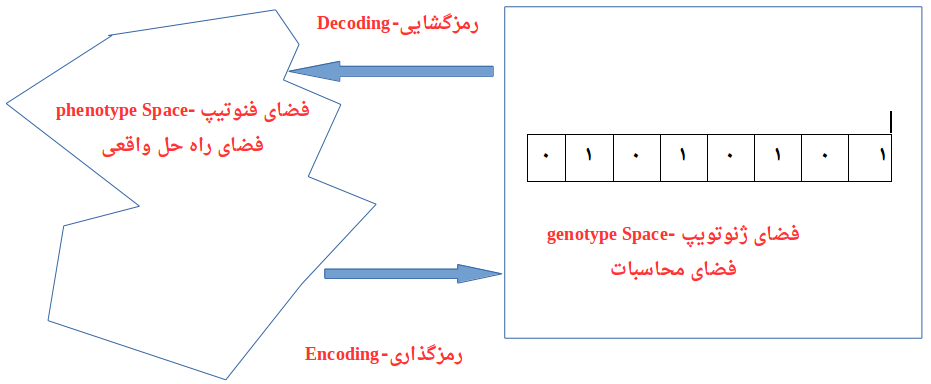
برای مثال در مسائله کوله پشتی 0/1 (0/1 Knapsack Problem).فضای فنوتیپ شامل راه حلهایی است که فقط شامل تعداد آیتم هایی است که از آیتم های موجد برداشته شده اند برداشته شدهاند.به هر حال ، در فضای ژنوتیپ مثال ذکر شده در بالا میتواند به عنوان یک رشته دودویی با طول n نمایش داده شود ( که در اینجا n تعداد آیتم هاست). صفر (۰) در موقعیت x نمایش میدهد که x امین (x th) آیتم برداشته شده است در حالیکه وجود 1 برعکس آن را نشان می دهد( x امین آیتم برداشته نشده است).این نمونهای است که در آن فضای ژنوتیپ و فنوتیپ با یکدیگری متفاوت هستند.
- تابع سازگاری (Fitness Function ) : یک تعریف ساده از تابع سازگاری تابعی است که راه حل را به عنوان ورودی دریافت می نماید و راه حل مناسب را به عنوان خروجی تولید میکند.در بعضی از موارد ، تابع سازگاری و تابع هدف یکسان هستند و در بعضی دیگر بر اساس مسائله ممکن است که متفاوت باشند.
- عملگر ژنتیکی(Genetic Operators ) : عملگرهای ژنتیکی ترکیب ژنتیکی فرزندان را تغییر میدهند .برای مثال میتوان به عملگر های انتخاب(selection) ، جهش(mutation) ،متقاطع (crossover)و غیره نام برد.
ساختار پایه الگوریتم های ژنتیک
ساختار پایه یک الگوریتم ژنتیک به شرح ذیل است :
از یک جمعیت اولیه شروع میکنیم ( که میتواند به صورت تصادفی یا شیوههای ابتکاری دیگر تولید شده باشد) .والدینی را از این جمعیت برای زاد و ولد انتخاب میکنیم.عملگرهای crossover و mutation (جهش) را روی والدین برای تولید نمودن فرزندان جدید اعمال میکنیم و سرانجام این فرزندان اشخاص موجود را در جمعیت جایگزین نموده و فرآیند تکرار میشود. در این روش الگوریتم های ژنتیک سعی میکنند تا شیوه تکامل بشری را تا حدی تقلید کند.
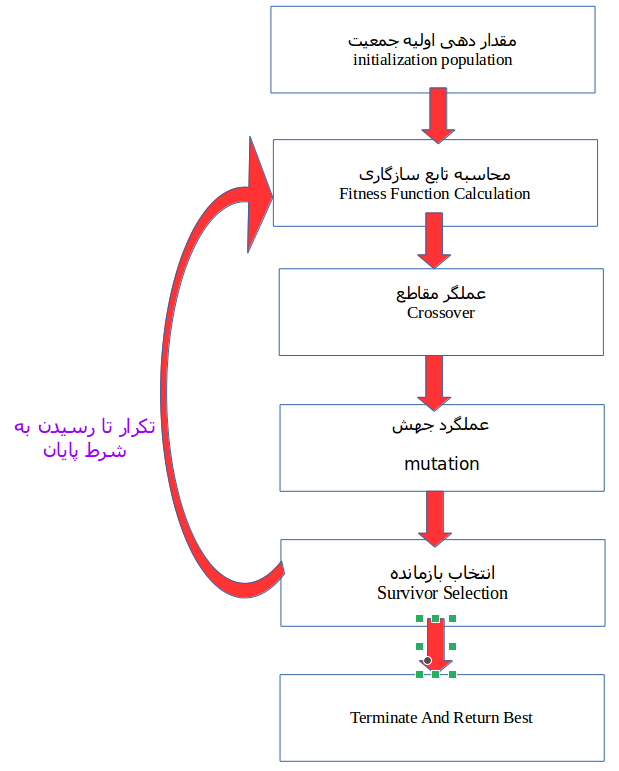
و در انتها شبه کدی که یک الگوریتم ژنتیک را شرح میدهد در زیر آورده شده است
GA()
initialize population
find fitness of population
while (termination criteria is reached) do
parent selection
crossover with probability pc
mutation with probability pm
decode and fitness calculation
survivor selection
find best
return best