IDS: Intrusion Detection System
intrusion detection system concepts and techniquesIDS: Intrusion Detection System
intrusion detection system concepts and techniques
مقدمهای بر الگوریتم های ژنتیک
مقدمهای بر الگوریتم های ژنتیک :
الگوریتم ژنتیک (Genetic Algorithm -GA) یک تکنیک بهینه سازی بر اساس جستجو میباشد که بر اصول ژنتیک و انتخاب طبیعی(Natural Selection) پایه گذاری شده است.این تکنیک به کرات برای یافتن راه حل بهینه یا نزدیک به بهینه مورد استفاده قرار میگیرد تا بدین وسیله مسائل مشکلی که ممکن است توسط روشهای دیگر در زمان طولانی حل شوند را در یک زمان مناسب و بهینه حل نماید.اغلب اوقات از این تکنیک در پژوهش ها و یادگیری ماشین برای حل مسائل بهینه سازی (optimization problems مسائلی که در آن بهترین راه حل از میان همه راه حلهای ممکن یافت می شود)استفاده میشود
مقدمه ای بر بهینه سازی :
الگوریتم ژنتیک (Genetic Algorithm -GA) یک تکنیک بهینه سازی بر اساس جستجو میباشد که بر اصول ژنتیک و انتخاب طبیعی(Natural Selection) پایه گذاری شده است.این تکنیک به کرات برای یافتن راه حل بهینه یا نزدیک به بهینه مورد استفاده قرار میگیرد تا بدین وسیله مسائل مشکلی که ممکن است توسط روشهای دیگر در زمان طولانی حل شوند را در یک زمان مناسب و بهینه حل نماید.اغلب اوقات از این تکنیک در پژوهش ها و یادگیری ماشین برای حل مسائل بهینه سازی (optimization problems مسائلی که در آن بهترین راه حل از میان همه راه حلهای ممکن یافت می شود)استفاده میشود
مقدمه ای بر بهینه سازی :
بهینه سازی پروسه ساخت یک چیز بهتر است.در هر پروسه ، یک مجموعه از ورودی ها داریم و یک مجموعه از خروجی ها که در شکل زیر نشان داده شدهاند

بهینه سازی به پیدا کردن مقادیری از ورودی ها اطلاق میشود به نحوی که بهترین مقادیر خروجی را بدست بیاوریم. تعریف بهترین از مسائله به مسائله دیگر متفاوت است اما در اصطلاح ریاضیات به حداکثر رساند یا به حداقل رساندن یک یا چند تابع هدف از طریق تغییر دادن پارامتر های ورودی اطلاق میشود.یک مجموعه از همه راه حلهای ممکن یا مقادیر ورودی میتواند فضای جستجو را تکشیل دهد.در این فضای جستجو یک نقطه یا یک مجموعه از نقاط که راه حل بهینه را فراهم میکنند پنهان شدهاند. وظیفه نهایی بهینه سازی پیدا کردن نقطه یا مجموعهای از نقاط در فضای جستجو است.
الگوریتم های ژنتیک چه هستند ؟
طبیعت همیشه یک منبع بزرگ از الهام برای همه نسل بشر بوده است.الگوریتم های ژنتیک الگوریتم هایی بر اساس جستجو هستند که بر پایه مفهوم انتخاب طبیعی و ژنتیک پایه گذاری شده است.الگوریتم های ژنتیک زیر مجموعهای از یک شاخه بسیار بزرگتر از محاسبات که معروف به محاسبات تکاملی (Evolutionary Computation) است میباشند.الگوریتم های ژنتیک بوسیله John Holان وی در دانشگاه میشیگان توسعه داده شد و از این الگوریتم ها برای حل مسائل مختلف بهینه سازی با درجه بالایی از موفقیت استفاده شده است.
در الگوریتم های ژنتیک یک مخزن یا مجموعه از راه حلهای ممکن برای مسائله داده شده داریم.این راه حلها تحت عملیات های نوترکیبی (recombination) و جهش(mutation) شبیه آنچه در ژنتیک طبیعی رخ میدهد ، فرزندان جدیدی تولید میکنند.این پروسه در نسل های مختلف تکرار میشود.به هر فرد ( یا راه حل کاندید) یک مقدار متناسب اختصاص داده می شود( بر اساس مقدار تابع هدف آن) و افراد شاخص شانس بالاتری برای زاد و ولد و تولید افراد شاخص تر دارند. این درواقع تعریف تئوری داروین است که معتقد به بقای نسل اصلحتر میباشد.در این روش بهترین افراد یا راه حلها در نسل های ایجاد شده استخراج میشوند.این کار تا رسیدن به یک معیار توقف ادامه مییابد.الگوریتم های ژنتیک به اندازه کافی در طبیعت تصادفی هستند، اما آنها عملکرد خیلی بهتری از جستجوی محلی تصادفی دارند( که در آن ما فقط راه حلهای تصادفی مختلف را مورد برآورد قرار میدهیم).
مزایای الگوریتم های ژنتیک :
الگوریتم های ژنتیک دارای مزیتهای متعددی هستند که آنها را فوقالعاده محبوب و مورد استفاده نموده است
- نیاز به هیچ اطلاعات فرعی ( مشتق شده) نیست .که ممکن است برای اغلب مسائل دنیای واقعی در دسترس نباشد.
- قابلیتهای بسیار خوب برای موازی سازی دارد
- هر دو تابع های گسسته و پیوسته را بهینه سازی می نماید و همچنین مسائل چند هدفه را ( multi-objective)0
- لیستی از راه حلهای خوب را بجای یک راه حل یکتا تهیه میکنند
- همیشه یک راه حل برای مسائل دارند در طول زمان بهتر میشود
- هنگامی که فضای جستجو بسیار بزرگ است و تعداد زیادی از پارامتر ها در مسائله درگیر هستند مفید هستند
محدودیتهای الگوریتم های ژنتیک :
شبیه هر تکنیک دیگری الگوریتم های ژنتیک از یکسری محدودیتها رنج میبرند که شامل موارد زیر است :
شبیه هر تکنیک دیگری الگوریتم های ژنتیک از یکسری محدودیتها رنج میبرند که شامل موارد زیر است :
- الگوریتم های ژنتیک برای همه مسائل مناسب نیستند مخصوصاً آن دسته از مسائلی که ساده هستند و اطلاعات مشتق شده (derivative information) برای آنها موجود باشد
- مقدار متناسب ( مناسب) مکرراً محاسبه میشود که ممکن است برای بعضی از مسائل محاسباتی پر هزینه و گران باشد
- تصادفی بودن باعث میشود که هیچ تضمینی برای بهینه بودن یا کیفیت راه حل وجود نداشته باشد
- اگر درست اجرا نشود الگوریتم ژنتیک ممکن است که یک راه حل بهینه را بوجود نیاورد.
انگیزه برای استفاده از الگوریتم های ژنتیک :
الگوریتم های ژنتیک این توان را دارند که راه حلهایی به اندازه کافی سریع و به اندازه کافی خوب فراهم کنند.این ویژگیها باعث میشود که الگوریتم های ژنتیک برای استفاده در حل مسائل مربوط به بهینه سازی جذاب باشند.دلایلی مورد نیاز بودن الگوریتم های ژنتیک به شرح ذیل میباشد :
حل مسائل مشکل
در علوم کامپیوتری ، مجموعهای از مسائل موجود است که در دسته NP-Hard قرار می گیرند.و این بدان معناست که حتی قویترین سیستمهای محاسبه ای برای حل این مسائل نیازی صرف زمان خیلی طلانی دارند ( حتی سالها).در چنین سناریوهایی یک ابزار ثابت شده و خوب برای فراهم نمودن یک راه حل نزدیک به بهینه در یک مدت زمان کوتاه است.
شکست روشهای مبتنی بر گرادیان.
روشهای محاسبه قدیمی با شروع در یک نقطه تصادفی و حرکت در یک جهت از گرادیان تا رسید به بالاترین مکان کار می کنند.این تکنیک برای توابع هدفی که تنها یک نقطه اوج دارند مثل تابع هزینه در رگرسیون خطی.اما در اغلط موقعیت های دنیای واقعی با مسائل خیلی پیچیدهای سر و کار داریم که به landscapes (منظره ها) معروف هستند ، که از تعدادی زیادی قله و دره ساخته شده اند.که باعث میشوند متد های قدیمی که شرح داده شده در مواجه با آن موفق نباشند. این متدها از گرایش ذاتی به گیر افتادن در نقطه قله مطلوب محلی رنج می برند.این مطلب در شکل زیر نمایش داده شده است :
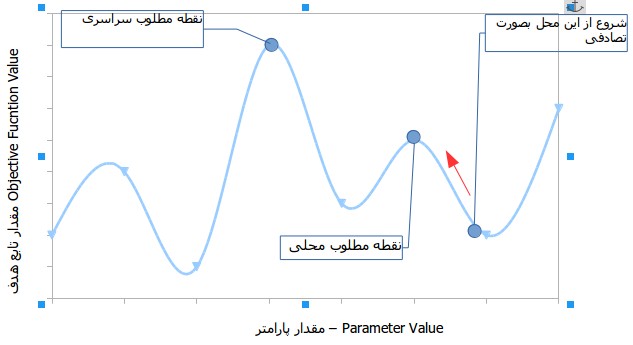
بدست آوردن راه حل خوب با سرعت مناسب
برخی از مسائل مشکل مثل مسائله فروشنده دورهگرد (Travelling Salesperson Problem -TSP) دارای کاربرد در دنیای واقعی هستند.مثل پیدا کردن مسیر و طراحی VLSI .حالا فرض کنید که شما از سیستم ناوبری GPS استفاده میکنید و برای محاسبه مسیر بهینه از مبداء به مقصد چند دقیقه ( یا حتی چند ساعت) صرف میکنید . تأخیر در اینگونه برنامههای کاربردی در دنیای واقعی پذیرفتی نیست پس ش یک راه حل به اندازه کافی خوب راه حلی است که به اندازه کافی هم سریع باشد
الگوریتم های ژنتیک این توان را دارند که راه حلهایی به اندازه کافی سریع و به اندازه کافی خوب فراهم کنند.این ویژگیها باعث میشود که الگوریتم های ژنتیک برای استفاده در حل مسائل مربوط به بهینه سازی جذاب باشند.دلایلی مورد نیاز بودن الگوریتم های ژنتیک به شرح ذیل میباشد :
حل مسائل مشکل
در علوم کامپیوتری ، مجموعهای از مسائل موجود است که در دسته NP-Hard قرار می گیرند.و این بدان معناست که حتی قویترین سیستمهای محاسبه ای برای حل این مسائل نیازی صرف زمان خیلی طلانی دارند ( حتی سالها).در چنین سناریوهایی یک ابزار ثابت شده و خوب برای فراهم نمودن یک راه حل نزدیک به بهینه در یک مدت زمان کوتاه است.
شکست روشهای مبتنی بر گرادیان.
روشهای محاسبه قدیمی با شروع در یک نقطه تصادفی و حرکت در یک جهت از گرادیان تا رسید به بالاترین مکان کار می کنند.این تکنیک برای توابع هدفی که تنها یک نقطه اوج دارند مثل تابع هزینه در رگرسیون خطی.اما در اغلط موقعیت های دنیای واقعی با مسائل خیلی پیچیدهای سر و کار داریم که به landscapes (منظره ها) معروف هستند ، که از تعدادی زیادی قله و دره ساخته شده اند.که باعث میشوند متد های قدیمی که شرح داده شده در مواجه با آن موفق نباشند. این متدها از گرایش ذاتی به گیر افتادن در نقطه قله مطلوب محلی رنج می برند.این مطلب در شکل زیر نمایش داده شده است :
بدست آوردن راه حل خوب با سرعت مناسب
برخی از مسائل مشکل مثل مسائله فروشنده دورهگرد (Travelling Salesperson Problem -TSP) دارای کاربرد در دنیای واقعی هستند.مثل پیدا کردن مسیر و طراحی VLSI .حالا فرض کنید که شما از سیستم ناوبری GPS استفاده میکنید و برای محاسبه مسیر بهینه از مبداء به مقصد چند دقیقه ( یا حتی چند ساعت) صرف میکنید . تأخیر در اینگونه برنامههای کاربردی در دنیای واقعی پذیرفتی نیست پس ش یک راه حل به اندازه کافی خوب راه حلی است که به اندازه کافی هم سریع باشد
معرفی کتاب Artificial intelligence illuminated
کتاب Artificial Intelligence Illuminated یک مررور کلی بر پیشنه و تاریخچه هوش مصنوعی دارد به مسائلی در خصوص هوش مصنوعی و تأکید بر اهمیت آن در مسائل امروزی و بطور بالقوه در آینده میپردازد.کتاب به مجموعهای از تکنیک های هوش مصنوعی و متدولوژی ها شامل بازی ، عامل های هوشمند ، یادگیری ماشین ، الگوریتم های ژنتیک و زندگی هوشمند میپردازد . مطالب به شکلی ساده و قابل فهم در این کتاب آورده شدهاند و نویسنده بر شرح اینکه چگونه هوش مصنوعی و تکنیک های مربوط به آن از سیستمهای طبیعی استخراج میشوند و به آنها وابسته هستند متمرکز میباشد.

برای اطلاعات بیشتر در خصوص این کتاب می توانید به لینک زیر مراجعه نمایید:
ارزیابی سیستمهای تشیخص نفوذ
ارزیابی سیستمهای تشیخص نفوذ
چندین ارزیابی مستقل در خصوص سیستمهای تشخیص نفوذ انجام شده است که معروف ترین آنها ارزیابی های آزمایشگاه Mit Lincoln میباشد [MIT Lincoln Laboratory, 2000]. این ارزیابی ها مورد پشتیبانی و حمایت مؤسسه DARPA(Defense Advanced Research Projects Agency) بود و هدف نهایی آنها ارزیابی تحقیقات موجود در خصوص تشخیص نفوذ میباشد.در مجموع سه ارزیابی در سالهای 1998 ، 1999 و 2000 انجام شده است.
اگر چه موضوعات مورد توجه این ارزیابی ها برای هر سال قدری متفاوت است اما از نظر متدولوژی های آزمایش و تست تفریبا یکسان هستند. در سال 1998 برای ارزیابی آزمایشگاه Lincoln یک بستر آزمایشی برای تقلید از یک دنیای واقعی شبکه کامپیوتری بوجود آمد.تعاملات انسانی با هاست های مختلف با استفاده از اسکریپت های مختلف شبیه سازی شد. هاست های مختلف قوانین مختلف و مربوط به خود را داشتند .برای نمونه کامپیوتر متعلق به یک منشی برنامههای اداری معمول را اجرا مینمود و هاست های مربوط به توسعه دهندگان سیستم ابزارهای توسعه نرمافزار را اجرا می نمودند.بعضی از این هاست ماشینهای واقعی بودند و برخی دیگر شبینه سازی شده بودند. حداکثر تلاش انجام شده بود تا اطمینان حاصل شود که بستر آزمایشی شبکه تا حد زیادی برای مشاهده کنندگاه خارجی واقعی به نظر برسد.
در طول عملیات در بستر آزمایشگاهی ، دادههای مختلف بازرسی جمع آوری میشوند .همه ترافیک شبکه وسیله tcpdump جمع آوری میشود [tcpdump, 2002].همچنین فایلهای لاگ سیستمی مربوط به هاست ها نیز ذخیره ضبط میشوند.علاوه بر اینها بعضی از هاست ها که سیستم عامل سولاریس را اجرا می نمودند شامل یک ماژول پایه امنیتی بودند (Basic Security Module). این ماژول پایه امنیتی در میان چیز های دیگر هر درخواست توسط سیستم را مورد نظارت قرار میداد. در نهایت هم هر حمله به صراحت ثبت می گردید تا یک فایل حقیقت ایجاد و تهیه شود (truth file) که بعداً برای امتیازدهی به سیستمهای تشخیص نفوذ مورد استفاده قرار گیرد.
برای ارزیابی دو مجموعه داده مختلف تولید میشوند. امتیاز دهی واقعی به سیستمهای تشخیص نفوذ به صورت آفلاین انجام میشود. اولین مجموعه داده برای شرکت کنندگان همراه با فایل حقیقت متناظرشان قبل از آزمایش واقعی فراهم آورده میشود.ایده این بود که به شرکت کنندگان یک شانس برای تنظیمات سیستمهای خود داده شود.این مجموعه داده همچنین برای آموزش دادن سیستمهای تشخیص ناهنهجاری (anomaly detection systems) مورد استفاده قرار میگیرد. فایل حقیقت این مجموعه در امتیاز دهی سنسور ها مورد استفاده قرار میگیرد و تا زمانی که ارزیابی پایان نیافته است محتوای آن برای شرکت کنندگان فاش نمیشود.نتیجه ارزیابی Lincoln Lab 1998 یک معیار برای اندازهگیری نرخ شناسایی صحیح و ناصحیح سنسورها میباشد.
آزمایشگاه lincoln ارزیابی مشابهی را در سال 1999 انجام داد.تنظیمات و راه اندازی آزمون تقریباً مشابه سال قبل بود .و تفاوتی که وجود داشت این بود که حملات انجام شده هوشمندانه تر بودند.
این دو مجموعه داده معروف به KDD98 و KDD99 هستند که هر دو توسط Mit Lincoln Lap ثبت شدهاند.
در سال 1999 برنامه ارزیابی تشخیص نفوذ DARPA توسط آزمایشگاههای MIT Lincoln آماده و مدیریت شد.هدف هم این بود :بررسی و ارزیابی تحقیقات در زیمه تشخیص نفوذ.یک مجموعه استاندارد از دادهها مورد بازرسی قرار گرفتند که شامل طیف وسیعی از نفوذ هایی بود که در یک محیط شبکه نظامی شبیه سازی شده بودند. KDD1999 از یک نسخه از این مجموعه داده استفاده میکند.
و درواقع این مجموعه های داده شامل بررسی هفتهها ترافیک شبکه و حملات مختلف در یک محیط شبکه نظامی شبینه سازی شده میباشند.برای دریافت اطلاعات بیشتر میتوانید به آدرس http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html مراجعه نمایید.البته در پایان ذکر این نکته را ضروری میدانم که KDD98 و KDD99 تنها دیتا ست های موجود برای تست محیط های تشخیص نفوذ نیستند و بستگی به نوع سیستم تشخیص نفوذ و محیط و نیازمندی های که وجود دارد دیتاست های دیگری نیز وجود دارند.
چندین ارزیابی مستقل در خصوص سیستمهای تشخیص نفوذ انجام شده است که معروف ترین آنها ارزیابی های آزمایشگاه Mit Lincoln میباشد [MIT Lincoln Laboratory, 2000]. این ارزیابی ها مورد پشتیبانی و حمایت مؤسسه DARPA(Defense Advanced Research Projects Agency) بود و هدف نهایی آنها ارزیابی تحقیقات موجود در خصوص تشخیص نفوذ میباشد.در مجموع سه ارزیابی در سالهای 1998 ، 1999 و 2000 انجام شده است.
اگر چه موضوعات مورد توجه این ارزیابی ها برای هر سال قدری متفاوت است اما از نظر متدولوژی های آزمایش و تست تفریبا یکسان هستند. در سال 1998 برای ارزیابی آزمایشگاه Lincoln یک بستر آزمایشی برای تقلید از یک دنیای واقعی شبکه کامپیوتری بوجود آمد.تعاملات انسانی با هاست های مختلف با استفاده از اسکریپت های مختلف شبیه سازی شد. هاست های مختلف قوانین مختلف و مربوط به خود را داشتند .برای نمونه کامپیوتر متعلق به یک منشی برنامههای اداری معمول را اجرا مینمود و هاست های مربوط به توسعه دهندگان سیستم ابزارهای توسعه نرمافزار را اجرا می نمودند.بعضی از این هاست ماشینهای واقعی بودند و برخی دیگر شبینه سازی شده بودند. حداکثر تلاش انجام شده بود تا اطمینان حاصل شود که بستر آزمایشی شبکه تا حد زیادی برای مشاهده کنندگاه خارجی واقعی به نظر برسد.
در طول عملیات در بستر آزمایشگاهی ، دادههای مختلف بازرسی جمع آوری میشوند .همه ترافیک شبکه وسیله tcpdump جمع آوری میشود [tcpdump, 2002].همچنین فایلهای لاگ سیستمی مربوط به هاست ها نیز ذخیره ضبط میشوند.علاوه بر اینها بعضی از هاست ها که سیستم عامل سولاریس را اجرا می نمودند شامل یک ماژول پایه امنیتی بودند (Basic Security Module). این ماژول پایه امنیتی در میان چیز های دیگر هر درخواست توسط سیستم را مورد نظارت قرار میداد. در نهایت هم هر حمله به صراحت ثبت می گردید تا یک فایل حقیقت ایجاد و تهیه شود (truth file) که بعداً برای امتیازدهی به سیستمهای تشخیص نفوذ مورد استفاده قرار گیرد.
برای ارزیابی دو مجموعه داده مختلف تولید میشوند. امتیاز دهی واقعی به سیستمهای تشخیص نفوذ به صورت آفلاین انجام میشود. اولین مجموعه داده برای شرکت کنندگان همراه با فایل حقیقت متناظرشان قبل از آزمایش واقعی فراهم آورده میشود.ایده این بود که به شرکت کنندگان یک شانس برای تنظیمات سیستمهای خود داده شود.این مجموعه داده همچنین برای آموزش دادن سیستمهای تشخیص ناهنهجاری (anomaly detection systems) مورد استفاده قرار میگیرد. فایل حقیقت این مجموعه در امتیاز دهی سنسور ها مورد استفاده قرار میگیرد و تا زمانی که ارزیابی پایان نیافته است محتوای آن برای شرکت کنندگان فاش نمیشود.نتیجه ارزیابی Lincoln Lab 1998 یک معیار برای اندازهگیری نرخ شناسایی صحیح و ناصحیح سنسورها میباشد.
آزمایشگاه lincoln ارزیابی مشابهی را در سال 1999 انجام داد.تنظیمات و راه اندازی آزمون تقریباً مشابه سال قبل بود .و تفاوتی که وجود داشت این بود که حملات انجام شده هوشمندانه تر بودند.
این دو مجموعه داده معروف به KDD98 و KDD99 هستند که هر دو توسط Mit Lincoln Lap ثبت شدهاند.
در سال 1999 برنامه ارزیابی تشخیص نفوذ DARPA توسط آزمایشگاههای MIT Lincoln آماده و مدیریت شد.هدف هم این بود :بررسی و ارزیابی تحقیقات در زیمه تشخیص نفوذ.یک مجموعه استاندارد از دادهها مورد بازرسی قرار گرفتند که شامل طیف وسیعی از نفوذ هایی بود که در یک محیط شبکه نظامی شبیه سازی شده بودند. KDD1999 از یک نسخه از این مجموعه داده استفاده میکند.
و درواقع این مجموعه های داده شامل بررسی هفتهها ترافیک شبکه و حملات مختلف در یک محیط شبکه نظامی شبینه سازی شده میباشند.برای دریافت اطلاعات بیشتر میتوانید به آدرس http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html مراجعه نمایید.البته در پایان ذکر این نکته را ضروری میدانم که KDD98 و KDD99 تنها دیتا ست های موجود برای تست محیط های تشخیص نفوذ نیستند و بستگی به نوع سیستم تشخیص نفوذ و محیط و نیازمندی های که وجود دارد دیتاست های دیگری نیز وجود دارند.